Alluxio在人工智能公共数据领域的应用调研
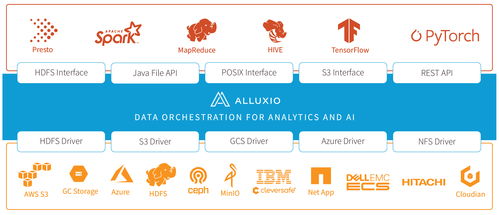
随着人工智能(AI)技术的飞速发展,数据已成为驱动模型训练与应用的核心燃料。特别是在处理大规模、多源、异构的公共数据集时,高效的数据管理与访问能力至关重要。Alluxio作为一种开源的数据编排层,为跨云、跨环境的数据访问提供了统一、高性能的解决方案。本文旨在调研Alluxio在人工智能公共数据场景下的应用价值、技术优势及实践案例。
一、人工智能公共数据的特点与挑战
人工智能公共数据通常指公开可获取、用于AI研究与开发的数据集,如图像库(如ImageNet)、文本语料、科学数据等。它们具有以下特点:
- 规模庞大:数据集常达TB甚至PB级,存储于分布式系统或云端。
- 多源异构:数据可能分散在不同存储系统(如HDFS、S3、本地磁盘)中,格式多样。
- 高并发访问:在AI训练或分析任务中,多个计算框架(如TensorFlow、PyTorch)需同时读取数据。
- 性能敏感:数据I/O速度直接影响模型训练效率,尤其在迭代式训练中。
这些特点带来了显著挑战:数据孤岛导致管理复杂;跨存储访问性能低下;计算与存储紧耦合限制了资源弹性。
二、Alluxio的核心价值:统一数据编排
Alluxio通过虚拟化底层存储系统,为上层应用提供统一的数据抽象层。其核心价值在于:
- 数据统一访问:无论数据存储在HDFS、AWS S3、Google Cloud Storage还是本地,Alluxio均可通过标准化API(如POSIX、REST)提供透明访问,简化AI工作流集成。
- 内存级加速:Alluxio利用内存和SSD构建分布式缓存层,将热数据(如公共数据集中频繁访问的样本)缓存在计算集群附近,大幅降低I/O延迟,加速AI训练任务。
- 弹性计算分离:通过解耦计算与存储,AI团队可独立扩展计算资源(如GPU集群)与存储资源,提升资源利用率和灵活性。
- 元数据管理:Alluxio提供高效的元数据服务,支持快速文件查找与目录操作,优化海量小文件场景(如图像数据集)的访问性能。
三、Alluxio在AI公共数据场景的技术优势
- 高性能数据读取:Alluxio的缓存机制可减少远程存储访问,尤其适用于重复读取公共数据集的训练作业。测试显示,在图像分类任务中,使用Alluxio缓存可将数据加载时间缩短50%以上。
- 跨云/混合云支持:公共数据常托管于多个云平台(如AWS、Azure),Alluxio支持跨云数据同步与缓存,使AI任务能无缝访问多地数据,避免数据迁移成本。
- 与AI生态集成:Alluxio与主流AI框架(如TensorFlow、PyTorch)和数据处理工具(如Spark、Presto)深度兼容,用户无需修改代码即可接入现有流程。
- 数据本地化优化:Alluxio智能感知计算任务位置,自动将数据缓存在任务节点附近,减少网络传输,提升GPU利用率。
四、实践案例与行业应用
- 学术研究场景:某大学AI实验室使用Alluxio管理公开的基因组数据集。数据存储在云端S3,而训练任务在本地GPU集群运行。通过Alluxio缓存,数据访问延迟从秒级降至毫秒级,模型训练时间缩短30%。
- 企业AI平台:一家科技公司构建了基于Alluxio的AI数据平台,统一管理来自公共数据库(如Kaggle)和内部数据。Alluxio提供了数据版本控制和访问控制功能,支持多团队协作开发。
- 跨区域训练:一家跨国机构利用Alluxio在多个区域的云上缓存公共图像数据,使全球分布的AI团队能就近访问数据,减少跨境传输开销。
五、挑战与展望
尽管Alluxio优势显著,但在AI公共数据场景仍需注意:缓存策略需根据数据访问模式精细调优;大规模部署时的运维复杂度较高。随着AI对实时数据流水线需求的增长,Alluxio可进一步强化与流处理框架(如Flink)的集成,并增强对非结构化数据(如视频、音频)的智能缓存支持。
Alluxio通过数据编排能力,为人工智能公共数据的管理与访问提供了高效、灵活的解决方案。它不仅加速了AI训练进程,还降低了跨平台数据整合的复杂度,正成为构建现代化AI基础设施的重要组件。对于依赖大规模公共数据集的AI团队,引入Alluxio有望显著提升生产力和资源效率。
最新产品

国双GridSum 企业级大数据与AI解决方案的典范
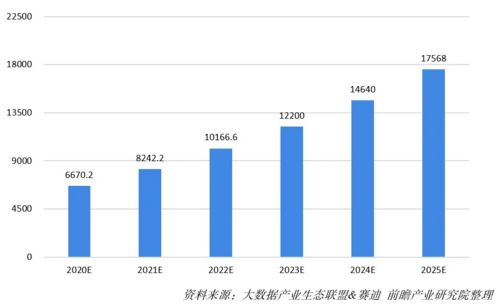
数字化转型浪潮 2020-2025年5G、人工智能、大数据、云计算及公共数据如何重塑经济格局

人工智能公共数据 撬动超6万亿美元投资潜力的核心钥匙

895项目动态 | 达观数据张江论道 人工智能公共数据驱动创新应用

大数据的四大宏观趋势与人工智能公共数据的协同演进
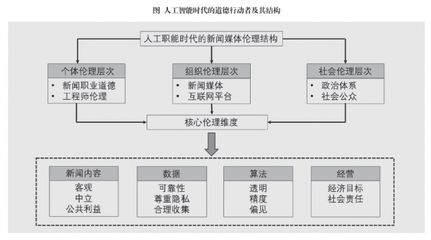
人工智能时代的新闻伦理 公共数据驱动下的行动与治理框架
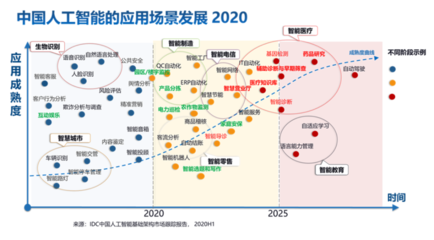
《2020年中国AI算力报告》揭示 人工智能公共数据与算力基建是未来发展关键

人工智能公共数据 图数据库在清华大学2020精品报告中的角色与价值

软杰荣膺2019深圳安博会无感支付十大品牌,以人工智能驱动公共数据创新

城云科技闪耀杭州智博会,人工智能公共数据创新获潘云鹤院士高度认可